Importing and Exporting data in python with panda
Panda is open source, the BSD-licensed library used for data analysis in Python programming language. It is build on top of two most essential python packages numpy and matplotlib. If you have not installed panda please go through this link and play with the code. Data acquisition is the process of loading and reading data from various sources. To read any data from python panda package, we need to consider two important factor i.e. format and file path. The format is the way data is encoded. Different encoding schemes can be determined by the extensions used in the file name like .csv for comma separated value, others common encoding are .json, .xlsx, .sql etc. File path tells where the data is stored. It could be at local machine or link of the data hosting website.
Importing a CSV file with Panda
Reading data in panda can be done quickly in three lines. In panda, read_csv() method can read in files with columns separated by commas into a pandas dataframe. Here’s an example of reading the dataset of prices of used car.
import pandas as pd
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data"
df = pd.read_csv(url)
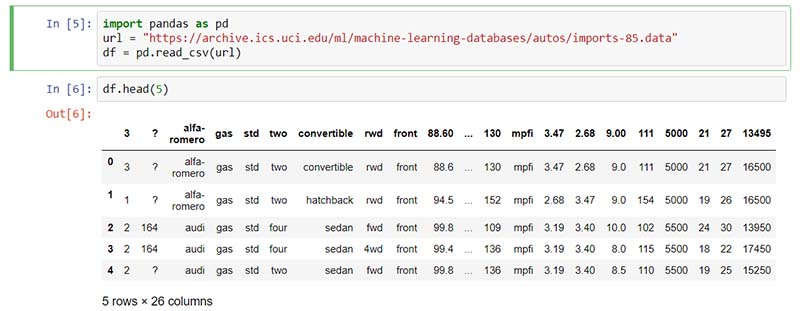
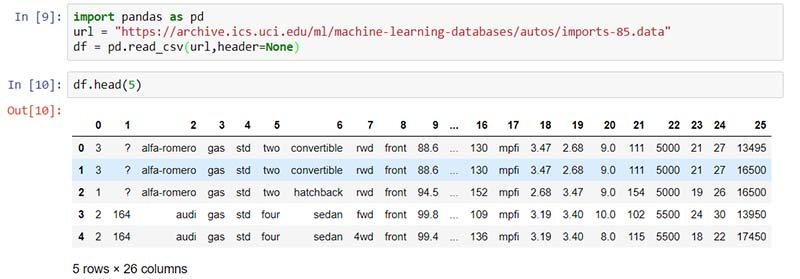
Importing a CSV file without the header in Panda
The data does not include headers, we can add an argument ” headers = None” inside the “read_csv()” method, so that pandas will not automatically set the first row as a header as shown in the image above. But, Panda automatically set the column header as a list of integers as shown in the image below.
import pandas as pd
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data"
df = pd.read_csv(url,header=None)
Printing the dataframe
df prints the entire dataframe. (not recommended for large dataset)
df.head(n) to show the first n rows of the dataframe.
df.tail(n) to show bottom n rows of the dataframe.
Adding Headers in Panda
It is difficult to work with dataframe without meaningful column names, however column names can be assigned in pandas. You can replace the default header by df.columns = headers

df.columns.values show the headers in your CSV file.

Exporting a Panda dataframe to CSV
After we have done some operations in the dataframe we may want to export our dataframe to the new CSV file. This can simply be done by using methods to_csv(). The implementation is shown below:
#Export to csv
path = "C:/Users/saugat/Desktop/python/extracted_automobile.csv"
df.to_csv(path)OR
#Export to csv
path = "C:\\Users\\saugat\\Desktop\\python\\extracted_automobile_next.csv"
df.to_csv(path)Note: path file should contain two backward slashes or forward slash otherwise the Unicode error will occur.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: while extracting csv pandaSimilarly, data could be read and save in other formats like JSON, Excel, sql etc.
2 thoughts on “Importing and Exporting data in python with panda”
thank you!
Write more, thats all I have to say. Literally, it seems as though you
relied on the video to make your point. You obviously know what youre talking about, why
throw away your intelligence on just posting videos to your blog when you
could be giving us something enlightening to read?